パート1:信頼性の高い設計へのアプローチ:故障の回避
Texas Instruments、Freescale、およ びInfineonからの「安全な」マイクロコント ローラの発表をうけて、安全性に不可欠なシ ステムの信頼性と冗長性を支える理論と実 用上のテクニックを網羅する最初の部品を、 当社はシリーズで提供します。
20世紀の最後の四半世紀で、「コンピュータ」の世界は信頼 性の欠如と同意になってしまいました。 システムに故障が発 生した場合は、常にコンピュータがミスを犯していました。 こ れはしばしば根拠のない認識であり、プログラマまたはオペ レータが犯す人的なエラーをよくカバーする都合の良い方法 となっていました。 コンピュータは私たちの失敗のスケー プゴートにされ、いわゆる「コンピュータのエラー」が傷害事 故や死亡事故につながらないかぎり、私たちはこのような状 況に耐えてきました。 しかし技術は変化し、コンピュータは自 動車にそして飛行機に搭載されて移動するようになり、 ウインドワイパーやナビゲーションな ど、安全性に不可欠な機能 を制御するのに使用されるようになってきました。 フライト制 御システムがコンピュータ化されるようになると、すべての状 況が変化しました。最初は軍事用の航空機に、次にAirbus A320のような民間航空機に導入されるようになりました。 今日では、自動車にもマイクロコントローラが搭載され、緊急 ブレーキやエアバッグ操作などの安全に不可欠な機能を担 っています。 最近では、Googleが完全無人操縦の自動車の 実用化計画を発表しています。 このようなあらゆる動向を受 けて、人々はコンピュータのエラーはどうなっているのだろ うかという疑問を抱くようになっています。 幸いなことに、航 空機メーカーや自動車メーカーは、多数の死亡者を伴う航空 機の墜落やハイウェイでの衝突事故を、単なる「コンピュータ のエラー」で済ませるわけにはいかないことを、早い段階か ら認識していました。 多くの研究者が、コンピュータを「完全 無欠」なものにしようとこの50年間奮闘してきました。その 結果、2つの解決方法を見出しました。1つは故障の回避で、 もう1つはマシンインテリジェンスと耐故障性の向上です。
コンセプトとしてのコンピュータの信頼性の定義は曖昧で、コ ンピュータのオペレータとユーザの数だけ存在します。 これ は視点のレベルによって異なり、一般にコンピュータ設置の責 任者はスループットが要件を満たしているという理由で、その システムは信頼性が高いと考えがちです。 オペレータの眼は より厳しく、このスループットを達成するには、ミスを修正し、 メンテナンスエンジニアを呼んでコンポーネントを頻繁に交換 しなければならないと考えます。 メンテナンスエンジニアは、 予防対策と同時に潜在的な故障を特定して、まだ「下流」のエ ラーを引き起こすには至っていないその他の故障を除去す るため、システム全体を信頼性のないものとしてみなします。 信頼性に対するこの従来の人的アプローチは、飛行制御の ような安全性が重要となるシステムに対しては不十分です。
信頼性の定義
- 信頼性とは、おそらく特定のシステムが所 定の条件下で所定の期間必要な機能を 実行することと考えられています。
- 故障は、システムが指定されたタスクを正しく実行で きないことの直接の原因です。 故障は、ハードウェア、 タイミングまたはソフトウェア(バグ)に存在します。 永 続的(ハード)または過渡的な性質を持っています。
- 故障とは、欠点の存在により、システムの仕様から 外れてしまうことです。 これが実際に意味するこ とは、正しい状態の処理が続いた後でプロセッサ 自体が不正な状態に陥ることを示しています。
- エラーは、プログラム計算の特定部分のエラーの 形で現れるマシンの明確な故障のことです。
システムを設計するときは、故障の原因となりそうなもの を考慮する必要があり、それらを「脅威」と呼びます。
- 脅威は、故障を発生させるストレス、通常の環境、異常 な環境、または設計上のエラーによるものがあります。
信頼性に関する数学的な関数を求めるには、2つの主要な 前提を置きます。 その前提とは、デバイスの故障がランダ ムに発生しそれが統計的に独立したものであることと、1 時間あたりの件数で表される故障の発生率が機器の寿命 期間中一定であることです。 これらの前提はどちらも当て にならないものですが、一定の条件が満たされるなら、シ ステムの分析という目的に対して合理的な有効性を持ちま す。 統計上の独立性とは、1つのコンポーネントの故障が 隣接するコンポーネントにストレスを与えることがなく、し たがって故障率の上昇を引き起こさないという前提です。

図1 時間によるコンポーネントの故障率
コンピュータがディスクリートのトランジスタや抵抗器等で 構成されている場合、コンデンサの短絡による故障により、 トランジスタが過負荷の状態になり、さらにそれに連鎖す る故障が引き起こされます。 ICロジック部品は、連鎖ダメ ージの影響を比較的受けることなく、信頼性モデルにより 近い性格を持っています。 故障率を一定にするための要件
として、システム寿命の初期の「バーンイン」および「へた り」のフェーズ(図1)を除外し、「バスタブ」カーブの水平な 部分のみを使用することがあげられます。 バーンインフェ ーズで、本質的に故障のあるコンポーネント、ハードウェア 設計上のエラー、プログラムの「バグ」がすべて除去されま す。 したがって、非冗長システムモジュールの時間との関連 における理論的な信頼度は、以下の公式で求められます。
『 R(t) = e-λt 』 は一定の故障率
この公式により、図に示すような指数曲線が得られます。 2. 理論上のこのモジュールの信頼度は十分に高く、時 間 = 0の場合はR(t) = 1となり、稼働期間中のシステム

図2 単一ユニットの信頼度
は稼働期間中の一定の故障率の領域に入ります(図1)。
故障の回避

「Googleが完全無人操縦の自動車の実用化計画を発表」
従来の故障回避策または耐故障性の 目的は、個別のコンポーネントを改良 し、コンポーネントのMTBFを改善 することで、システムのMTBFを延長することでした。 これ は、必要となる機器の寿命またはミッション期間がシステムの MTBFよりもはるかに短くなるポイントで実現されるもので、 その結果得られるシステムの正常稼動率は、たとえば90-99 %となります。 一般に、軍用航空機の分野で特別に計算の基 礎として使用されるミッション時間では、MTBFは数時間にす ぎません。 故障回避は、次のいくつかの方法で実現されます。
- コンポーネントの品質管理。 今日では、これは偽 造部品に対する警戒の強化を意味しています。
- 大型のコンポーネントの定格引き下げ。電源能力 のたとえば10 %しか使用しないようにします。
- 自動車または軍需品の使用温度範 囲に対応した部品の使用。
- 冷却システムなどを使用した環境ストレスの軽減。
- ジョブを実行するのに最低限のコンポーネントの使用。 すなわち冗長性を廃して設計効率を向上させます。
これらのテクニックは軍需品で広く使用されるものです。軍需 品では軽量化の要件がすべての優先されるためです。 誘導ミ サイルのように、時間単位、ときには分単位または秒単位で測 定されることの多い武器システムのミッション時間において は、長期的な信頼度のニーズは通常二次的な関心事です。 軍 隊では、長期的な電源切断中の劣化が少ないことのほうがよ り重視されます。 民間部門に比べて、安全性は軽視されます。
民間航空機や自動車のプロジェクトでは、同様の短いミッ ション時間が使われることがありますが、故障回避のため の設計コストはかなりのものとなります。 幸いなことに、大 規模な集積回路は、セルフチェックシステム、オンボードの 「予備部品」、自動復旧などの耐故障性を低コストで提供 します。 非軍事用途では、耐故障性を追求することで無人 運転車両などの開発が進められ、それが可能なものとなる だけでなく安全性を高めるものとして実現されています。
パート2 では、 エアバスの航行システム、スペース シャトルの宇宙探検、およびロボットを利用した軌道 周回などを例にあげながら、耐故障性設計の理論上 および実用上の意味合いを探っていきます。
前号eTechでは、故障の回避 パート1を掲載しまし た。この号では、マイクロコントローラベースのシス テムで一時的で深刻な故障が発生した場合のハード ウェア設計のテクニックについて説明します。
耐故障性は、故障を回避するためにいくつもの対策がとられていても、や はり故障は発生するという前提にもとづいています。
- フェールセーフシステムは、故障が検出後の安全作業を継続すること はできず、誤った出力が行われることなく、予定通りにシャットダウンを 行ないます。
- 耐故障性システムでは、内蔵の機能(外部の補助なしで)により、一定 の故障が発生してもプログラムの実行と入出力機能が維持されます。
これは一見シンプルな定義に見えますが、現実のシステムで実現するの は実際には非常に困難です。 システムで永久的又は一時的な故障が発 生した場合、「正しい実行の継続」を安全に行うには、3つの要件を満た す必要があります。 その3つの要件は、
-
エラーの検出
システムは自己の誤りを検出する必要があります。 - 故障診断
システムは、アプリケーションプログラムを実行しながらエラーを検出 し、バイバス可能なコンポーネント又はモジュールのグループから故障 を切り離して、プロセッサの制御のもとで置き換えるかシャットダウン を行う必要があります。 - 故障からの復旧
故障の場所が特定されると、システムはその効果を排除するか最小化 するためのアクションを起こす必要があります。 一時的な故障では、 単に「リトライ」するだけで十分です。
上記の3つのプロセスができるだけ迅速に実行され、データスループット の中断を最小限に抑えられることが理想的です。 保護を目的とした冗長 性は、予備のハードウェアかソフトウェア又はその両方の形態をとり、故 障の発生後は直ちに復旧することが設計の目的です。 現実の問題として は、発生しうるあらゆるタイプのコンポーネントの単独の故障に対応する ことはほとんど不可能です。 故障によっては、致命的なシステムの損失 につながるものもあり、故障発生の可能性を受け入れ、可能なかぎり低い レベルにまで減らすことが、最善の方法です。 クロック発生器のような非 冗長回路では、耐故障性システムをダウンさせる単一故障の可能性を減 らすために、設計上特別な注意が払われます。
故障の検出と安全に処理される条件付き確率をカバーします。 「安全」 という用語は、悪影響を及ぼさないシステムシャットダウン(フェールセー フ)、又は操作を継続したまま故障したコンポーネントを切り離す(冗長ベ ースのシステムにおける耐故障性)ことを意味します。 この用語は、安全 側故障割合(SFF)とも呼ばれ、パーセンテージで表されます。 もちろん、 制御された機能の損失は許容されません。高速道路の走行中に運転手 のいない車を自動制御したらどうなるかを考えてみてください。 このシナ リオでは、耐故障性が唯一の選択肢です。
カバー率の概念により、可能性のあるすべての故障モードを検出し処理 する機能の観点から、特定の信頼性スキームを評価することができます。 予想される信頼性が達成可能な場合は、カバー範囲はほぼすべてとなり ます。
耐故障性と故障の回避は、互いに相容れないものではなく、特定の設計 に取り入れられた場合は、両方のテクニックを組み合わせることも可能 です。 冗長コンポーネントと予備モジュールの導入により、システムの信 頼性が自動的に向上するわけではありません。 実際のところ、低品質コ ンポーネントを冗長化することは、シンプルなシステムと比較しても、冗 長化システムがミッションを完遂する可能性が低くなります。 耐故障性を 備えたコンピューティングのメリットを最大限に発揮するには、最高品質 のコンポーネントと規定通りの設計が不可欠です。 これは、故障したコン ポーネントがなくなった場合でも、システムの可用性とミッション成功の 可能性が向上することを意味します。 2003年に打ち上げられ無人火星 探査車では、設計段階では可用性について特別な注意が払われ、予想さ れた耐用年数を何年も超えて活動しています。
シンプレックスとシンプレックス+診断
シンプレックス又は1oo1 (One out of One)システムは、故障を検出 する手段を全く持っていないため、安全性はかなり低下します。 シンプレ ックス+診断又は1oo1Dでは、回路のチェックが組み込まれており、プ ロセッサの動作を監視して、スピードが重視されるリアルタイムシステム に「オーバーヘッド」がないかチェックします。
「ウォッチドッグ」タイマーがしばしばプロセッサチップ又は個別の監視 デバイスの一部として組み込まれており、プロセッサの故障の検出に幅 広く使用されています。 プログラムが生成した信号が消失すると、通常 はシステムを強制的にリセットします。 これらの非常にシンプルなデバイ スは、電源の監視用にも組み込まれていることがよくあります。 新しい安 全標準であるISO26262及びIEC61508のニーズに対応するため、 より包括的なソリューションが必要となっています。 ARM® Cortex M3ベースのMCU [1]用のYogitech fRCPU、TriCore™プロセ ッサ用のInfi neon CIC61508 Signature Window Watchdog [2]などがその例です。 これらの診断デバイスにより、シンプレックス又 は1oo1システムは1oo1Dタイプに変換され、IEC61508 SIL3認 定システムを実現するために使用されます。 これは、SFFが99 %以上 で、出力がフェールセーフであることを意味します。
Texas Instruments TMS470M「セーフティー・マイコン」 Hercules™シリーズの一部で、シングルCortex-M3コアとエラー修 正及びセルフテストロジックのすべてを1つのチップに統合しています [3]。 ただし、SFFが60 %以下であるため、IEC61508安全基準は満 たしていません。 これは、コアが引き起こす可能性のある一時的又はシ ステム上のエラーの60 %以上を、エラーチェックロジックが検出するこ とができないためです。 このカバー率を上げるには、2つ以上のコアを 同じプログラムで実行して出力を比較するという、従来からあるテクニッ クを使用する方法があります。
マルチプロセッサモジュールの冗長性
コンピュータ制御システムの冗長性は、同じプログラムをそれぞれ「ロッ クステップ」で実行するプロセッサユニットの二重化(DMR又は2oo2) 、三重化(TMR or 2oo3)又は四重化(QMR又は2oo4)として従来より 知られてきました。 個別の比較又は決定ロジックは、プロセッサの大多数 が一致する場合のみアクチュエータを経由して出力できます。 これは、 決定ロジックがどの出力が不正であるかを識別できないため、両方のプ ロセッサをフェールセーフの方法でシャットダウンしなければならないた め、DMRには耐故障性がないことを意味します。 ただし、SFFが99 % 以上のDMRはSIL3基準を満たしています。 TMRは、1つのプロセッ サが故障しても、残りの2つが一致するかぎり動作は継続します。 (図1) QMRシステムは、パフォーマンスを低下させることなく2つの故障を処 理できなければなりません。 TMR及びQMRベースのシステムは、99 %以上のSFFを達成できる場合は、耐故障性を備えるためSIL4の基準 を満たす必要があります。

図1 トリプルモジュラ冗長性に基づくシングル耐故障性システム
Texas Instruments Hercules Cortex-R4Fベースの TMS570LSとRM48xマイクロコントローラには2つのプロセッサコ アが搭載されています。これらのコアは、同じプログラムをロックステッ プで実行しますが、そのうちの1つはスレーブとしてのみ機能するもの で、デバイスが生成する出力をチェックしてマスタの出力と比較します [3]。 マスタの出力のみが残りのシステムで使用可能となるため、DMR 1oo2システムは1つのデバイスとして構成することはできません。 代 わりに、IEC61508 SIL3のSFF99 %以上の基準を満たす1oo1D を構成することができます。
一時的で重大な故障
チェックシステムでエラーが発生した場合、例えば、飛来する宇宙線の 影響で偶発的にRAMセルが反転する可能性があります。 このような一 時的な故障の影響は、エラーを起こしたプログラム要素を再試行するこ とで解消できます。 再試行の機能はシステムに組み込まれている必要が あります。そうでない場合は、ハードウェアリソースが不正にシャットダウ ンします。 電気的なノイズの多い環境でシステムが稼働する場合でも、 これらの回路やソフトウェアが正しく機能して良好な結果を生み出すた めに、多大な時間と労力が費やされています。 もちろん、エラーチェック システムは「重大な」故障を迅速に検知して、無意味な再試行を回避す る必要もあります。
静的及び動的冗長性
決定回路の基本的なモジュールの冗長性は、通常すべてのモジュールが 「ホット」な状態で実行している静的なものとして分類されます。 プロセ ッサモジュールは、重大な故障が発生した場合は無視されるか、 電源がオフになります。
動的な冗長性には、ホットスタンバイ又はコールドスタンバイの予備ユニ ットがあり、故障検出ロジックとソフトウェアによって、必要に応じてイン とアウトが切り替えられます。 動的な冗長性は、スペースシャトル[4]と エアバス航空機[5]で幅広く使用されています。 エアバスでは、異なる マイクロコントローラプラットフォームと独立したチームが作成したソフ トウェアに基づくプロセッサモジュールによるダイバーシティを導入する ことで、さらにコモンモードの故障に対する予防措置が採られています。 これらのシステムはデュアルプロセッサ1oo1Dモジュールを搭載して おり、Herculesデュアルコアデバイスなどのシングルチップと置き換え られています。 たとえば、2つのチップを組み合わせて、耐故障性を備え たSIL4準拠の1oo2Dシステムを構築することができます。 (図 2)この ケースではプロセッサは「ホット」な状態で、共通のリセットなどの同じ入 力をどちらも受け入れます。 切り替えが命令されると、スタンバイユニッ トの出力が、故障が発生したモジュールの出力に取って代わります。 プ ロセッサクロックが同期されていない場合は、切り替え時にある程度の 規模のグリッチが発生します。
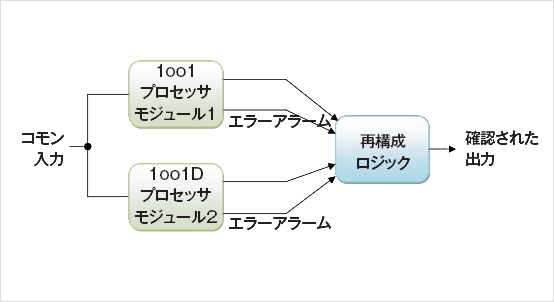
図2 2つのデュアルコアセーフティマイクロコントローラに基づくシングル耐故障性システム
まとめ
最近まで、耐故障性の開発には莫大なコストがかかるため、その概念は 主に航空機や宇宙船などの高コストプロジェクトに関連付けられていま した。 自動車のシステムでも、公道で無人自動車が現実のものになって くると、これらのテクニックが必要となるでしょう。 自動車及び産業用途 では、国際的な信頼性の標準であるISO26262とIEC61508に準拠 する必要があり、幸いなことに、新世代の「セーフティ」マイクロコントロ ーラで、エンジニアがこれらの標準に準拠した設計を行うことができま す。
| [1] | www.fr.yogitech.com |
| [2] | www.infineon.com |
| [3] | www.ti.com |
| [4] | 書籍:『 Redundancy Management Technique for Space Shuttle Computers』J.R.Sklaroff 、IBM Journal Research & Development、1976年 |
| [5] | 書籍:『 AIRBUS A320/A330/A340 Electrical Flight Controls』、『 A Family of Fault-Tolerant Systems』、Dominique Britxe、Pascal Traverse、IEEE 1993年 |
ページの先頭へ